The Database Versioning System and the series of Half-days


Today I am starting on the versioning system for individual tables rather than individual entries in order to lighten the load on the API and make better local caches of data for the client to load from. While I will retain the versioning system on individual entries in the tables for roll-back purposes I will be using this new versioning layer to handle all the updates for the server and client to cache.
I'll be heading down to hopefully sign a lease on Thursday which should make things a lot less stressful overall (a whole lot) so if that is all taken care of and the move is back on I can get back to working properly. I may be rolling with mostly half-days for a few weeks if this goes well, though. So progress will slow down a bit.
Anyway, to start out I need to think of how I want the versioning system to work. I was thinking about having one overall table that tracks the versions of every versioning table... so I can hit that endpoint and see if there's any need to hit any of the others. This could effectively reduce the update to one request if there's nothing to do.
As for the individual tables to track the updates, having one for every update could become a lot for the DB overall... unless I have some kind of cache in front of it and pull from that cache instead... hmm. Having all the updates lump together over a course of a week or something is another option but that could lead to gaps in the cached DBs unless I prevent them downloading until they are marked as Release ready... which would be fine in production but we're in dev where we want the updates to be instant.
With the cache I would have to make sure I have enough RAM to hold the data which isn't a problem most of the time since I have a lot of RAM in my servers... but this could become a large problem down the line with a whole lot of updates. This is logarithmic RAM usage, as there are more parts and features added there will be more updates per part and it could get pretty heavy. There are ways I could deal with this but I believe it will just over-complicate things.
Besides, I can add the cache later if I need it. It's just a matter of loading the JSON into memory. I could do that with our old friend Redis or some other in-memory database. Or I can cache the JSON as a file or as part of a flatfile DB which would have more overhead but less RAM requirement.
For now, in early dev I think I will keep it simple and just have an endpoint that has all the updates ready to go for each table. So the client will hit the Updates endpoint, figure out what needs to be updated and then go down the line firing requests to whatever secondary update tables to pull all the specific things that need updating.
Alternately I can write another socket server that is specifically for updates. It can handle all the versioning and data transfer itself, only polling the API on boot and when a hook is fired from the API when a table has changed. This socket server would act as a cache in itself, really. Holding all the update data in memory and transferring whatever the client needs based on the version data it supplies.
I think the best way to handle it for now would be the most straightforward. Easier to debug with less moving parts, then I can add on to it as needed later on once I have some testing done with it as it is.
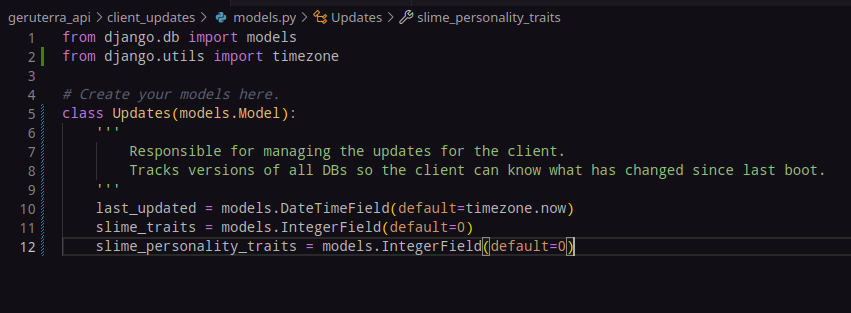
So the gist of it is that every time a table is updated, on save() it should create an entry in it's tracker database with the Date and ID. The primary key will be the version number as that will auto-increment on it's own. This will then update the Updates table with the current version of the table tracker. First the client will hit the Updates endpoint, this will tell the client what updates if any it needs, then pull the full json response from each table tracker endpoint that has a newer version than what's in it's cache.
For a moment I thought I had a better idea but it slipped away on me. Damn it. Maybe it will come back to me.
I will also have to write loaders on the client to read from the cache, in some cases on boot and in others on demand. These files are simple text but there could be thousands or hundreds of thousands of entries of data... so having to hold them in memory could become an issue, scanning through them could also be a little problematic.
There is SQLite. That would take less ram and allow me to more quickly fetch things from the client's local cache. It would require less boot time and eat less RAM as well. I'll have to look and see if the SQLite asset was ported to 4.x yet.
I did find something for adding Coroutines to Godot, requires the C# version but could be nice for the game server.
 GitHub
GitHubWhile I prefer to write everything myself, this will save me some weeks. Implementing this on the client will allow me to store a local cache of all the data the client will need that doesn't require oversight of the server. It should be more easily accessible without all the overhead of a json database as well and be able to find related data more quickly and easily.
I've experimented with this extension before, I think it should work fine. There's one of the potential headaches hypothetically dealt with.
Now I'll have to rewrite the current cache system to implement this, of course. Shouldn't be too hard. Just changing out JSON for SQL. It means a little more work per update but less work overall for the client to do and less RAM requirement so I can continue to try and support potatoes as target platforms.
Welp, better get over to the books and outline this whole thing there. Gotta keep my documentation up to date or what's the point of having it at all?

Now, I suppose the next part is adding that app to the API, tracking all versions. The initial boot should pull all objects from all DBs to start, so I wont need to retroactively add the updates from the work done thus far,
Thinking about it, I can just use the client_updates app I use for getting client-side data. It fits the purpose quite well and already has a lot of the stuff I need.
It occurs to me now that if I track the updates with a foreign key I can use a nested serializer to pull the exact data for the update right in the update itself, reducing the requests even further.
I could also have a boolean value tracking if there were sprite changes, though I would have to consider how those would be tracked. There must be a way to check if a value has been changed in the model when something is being updated... right?
This way we would only pull sprites when needed as well. Even less traffic.
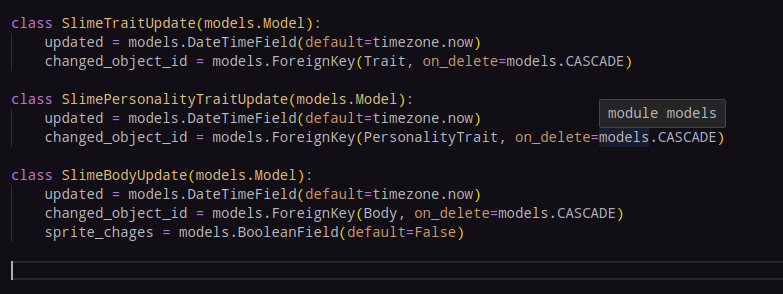
I will need to add some methods to these model classes... for now just string representations.
Chages, Nice typo, brain.
Then I need the post save hooks for each to update their version in the overall tracker.
It's lunchtime now, so I need to do that after... though I should probably make some calls first.
I realized that the people who wanted to schedule this phone interview got the year wrong and that might be the reason they never called. Also got my phone number wrong but I called them to make sure it was right. Ever since I left the city man, everything is all screwed up.
The update signal handler will be something like this:

Well, I had to actually CALL timezone.now() but yeah, working now.
All version update signals are in.
Now I need to serialize all of these.
Didn't even take a half day today.
Anyway, serializing...
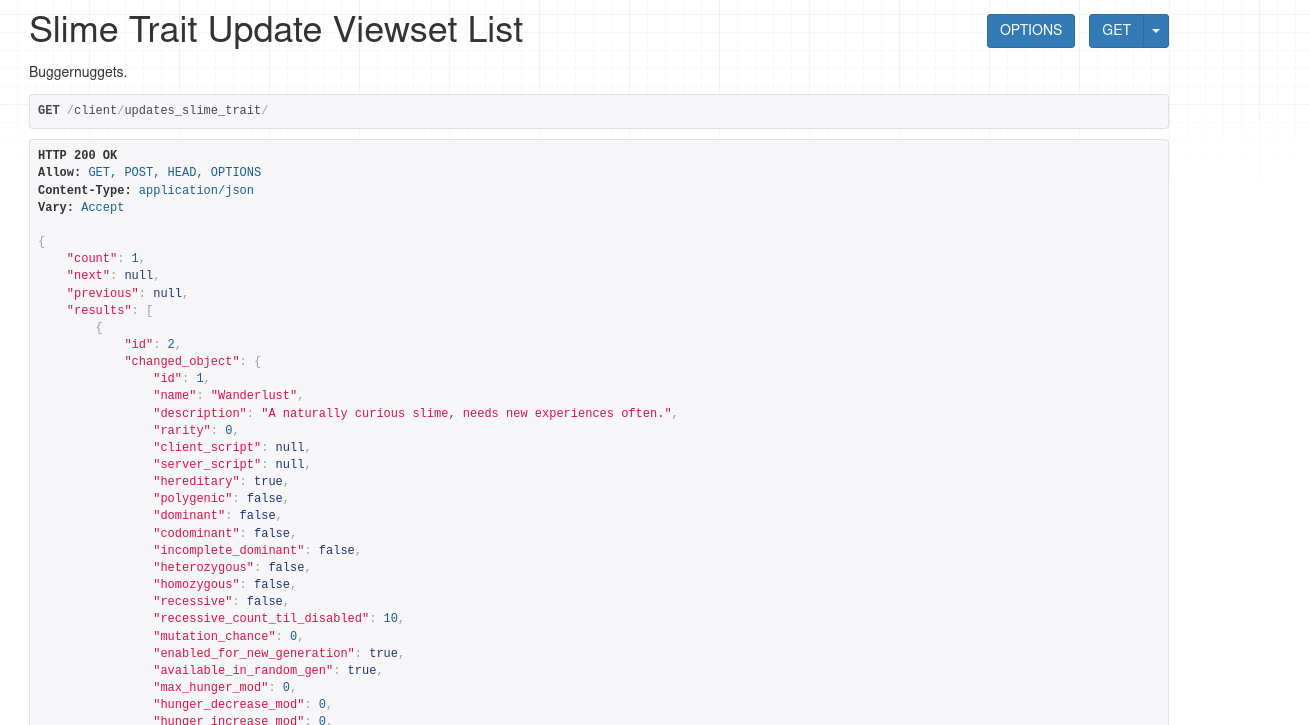
Now I have to serialize all the rest.

The client doesn't need most of the data.
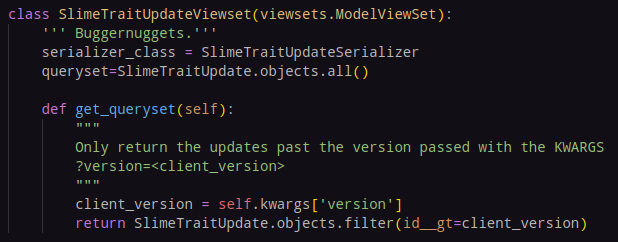
Now the client passes it's version here and only gets updates past that version.

Okay. Now that all of that is in place, the rest of it.
It's nearly 4 now, wonder if I will finish today.
Slime Update Serializers are in, players next, then viewsets, then URL registry... 4pm now. Might barely get this done in time.

The update serializers are done, I believe. On to view sets.
It's 5:04.

Probably gonna have some bugs here.
Added an All updates endpoint for each, just for testing really.
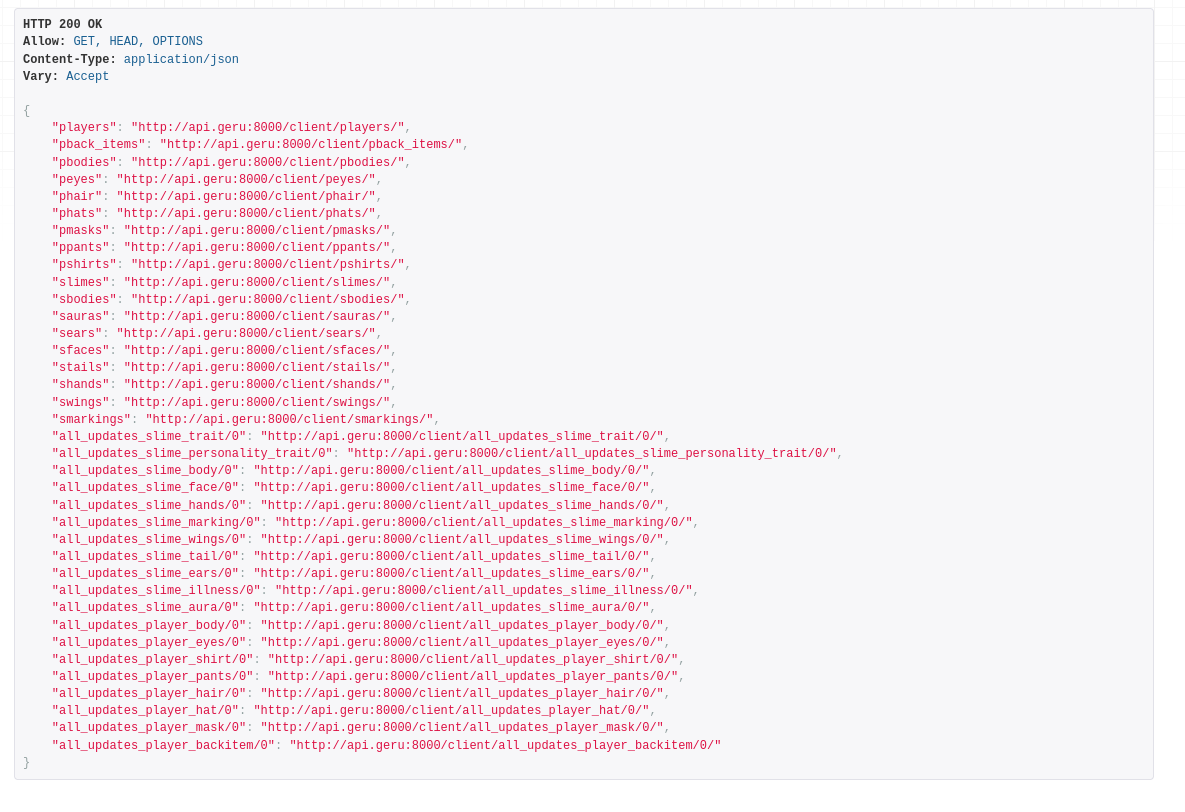
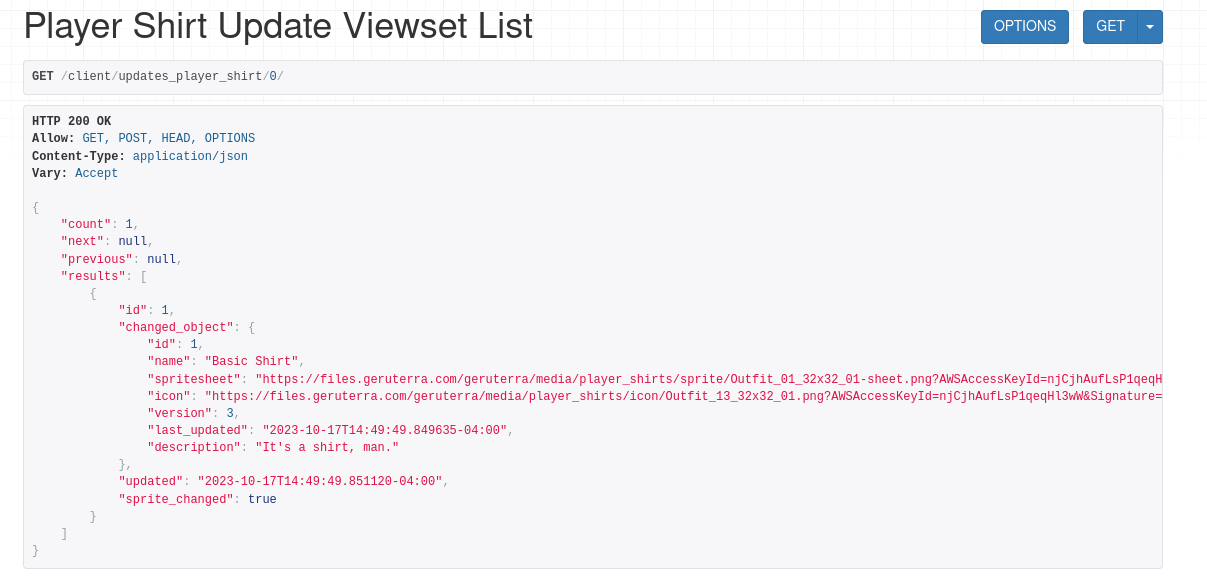
It's now 5:10, I will need to test these all tomorrow and then maybe get started on implementation of the client side databases and update handlers.
I also have to modify most of my serializers in the updater to get rid of a lot of data not relevant to the client.
This is going to be a lot of work but I believe it will be worth it in the end. Clockin' out.